CPU実験思い出し(コンパイラ・シミュ)
2022年のCPU実験の記録です.
書くの遅くない?

班員(コア係)の記事:
danook-programming.hatenablog.com
danook-programming.hatenablog.com
成果
弊班は35億6017万2340命令を52.82sで実行命令数と実行時間ともに1位でした.2022年度から本番が256×256での計測になりまして,過去の記録との比較用に128×128だと10億9776万4043命令を16sくらいです.大体3.3:1くらいのレートですね.
IRとそこで行った最適化はこんな感じです.ISAはリポジトリに上がってる通り変なことはしておらず,アーキテクチャは担当じゃないのでよくわかりません.
- 型検査後の構文木
- 融合変換
- K正規形
- 仮想アセンブリ(SSA)
- 末尾呼び出し最適化
- 不要定義削除
- ジャンプ短縮(後で説明)
- BB内不要store除去(コンパイラ実験の課題として.BB間じゃないので全然効果ない)
- アセンブリ
- 余ったレジスタ活用
- 不要ジャンプ除去(フォールスルー)
レイトレに特化して良いのはアーキテクチャの部分だけです.レイトレのコードに過剰に特化したコンパイラ最適化はしていません.十分に対象を一般化できるんだったら良いんですが,特定の手続きだけ検知して専用の最適化をかけるのってコンパイラがやったらベンチマークチートですよね.融合変換はこの中では一番怪しいですが,変換の対象は十分に小さいコード片なので問題ないという判断をしています.グローバル変数は,OCamlっぽい言語仕様なのにクロージャを使わない方が悪いので問題ないということにしています.
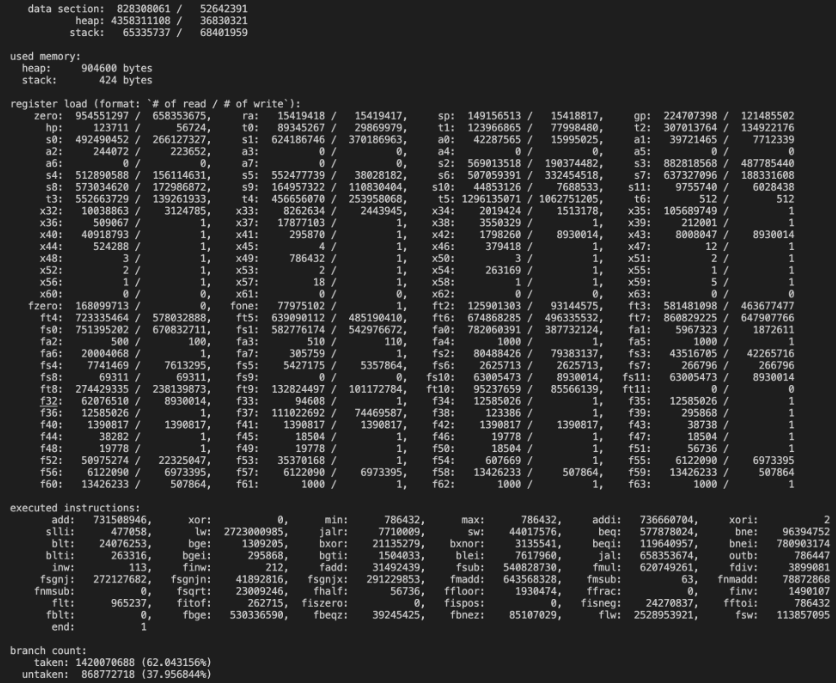
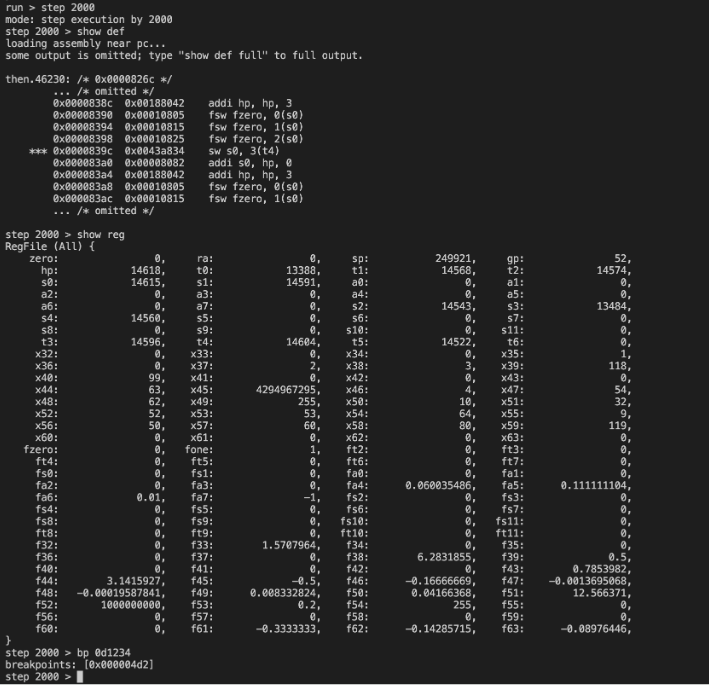
シミュレータは機械語入力でちょっとデバッガ的機能がついた物体になってます.次のようなことができます
- 実行時の命令引数による型検査を実施(これにより,レジスタ割り当てでsave/restoreを忘れていることに気づけた)
- メモリアクセスの場所の分類ごとのアクセス回数を集計(ヒープに頻繁にアクセスされていることがわかり,loop-invariantの発見,CSE/GVNの重要性を認識した)
- 命令ごとの実行回数の集計
- レジスタごとの使用回数の集計
当時のリポジトリは,対面講義のためだけの外出ごとに(電車内でも作業していたため)打たれたwip commitが邪魔なのと,(そもそもまともに動作するのが終盤なので)バージョンを戻す必要がなくcommitが雑につき新規リポジトリで公開しています.
https://github.com/s-ylide/cpuex2022-7-compiler
https://github.com/s-ylide/cpuex2022-7-simulator
mincamlに特有なこと
if式の処理が酷いです.1つの定義に帰着できるというのは大層なことですが,無駄な命令を発生させてまで実装でそれに従う必要はありません.
lwとswが即値を活用できるように実装を変更すると命令数をだいぶ減らせます.displacementを足してレジスタに入れて,その値をアドレスとしてメモリアクセスするより,直接displacement分先のメモリを読みに行ったほうが良いということです.レジスタの使用が減る上にフォワーディングを無くすことに繋がります.
レジスタ割り当てなどアセンブリ付近が本当にやばいので,一目見てわからなかったら自分で実装し直したほうが早く終わる気がします.
mincamlの「まともな」代替となる,CPU実験用のコンパイラを今作っています.これの使用が許可されると良いですね.
minrt.mlに特有なこと
TAの方々の尽力があり,パースが難しい部分が昔より改善しています.過去のCPU実験の記事で指摘されていたような内容はほとんど修正されています.今指摘しているような内容も数年後には変わっている可能性が大いにあります.
整数乗算と整数除算は左右シフトで置換可能なものしか現れません.print_intもちょっと頑張れば定数畳み込みできて消えるので,この内部実装で使うこともありません.
交差判定かなにかで,if xorがそこそこ頻発します.これ専用の命令を用意すると良いかもしれません.
複合命令とか増やしても結構命令数には余裕があるので,スケジューリングしてRISC-Vのcompressed命令とかVLIWをやるとお得かもしれないです.でもレイトレでは並列に実行できる計算がそんなに多くない気がします.
contest.sld以外にも20個くらいSLDファイルが提供されるので,先にこれらがまともに動くかのデバッグをすると良いでしょう.base.sldでは踏まないがcontest.sldでは踏む命令などもあり,シミュレータの機能が充実していれば単に実行を追う以上の情報を得られるはずです.
レイトレのアルゴリズム的に,各点ごとに,各方向,各オブジェクトごとに計算をするので,ループが何回も回っています(プログラムはアセンブリで10000行程度なのに数十億命令を実行するのはそのせい).ループ回数を適切に見積もれば最適化の余地があると思います.
タプル平坦化
私は結局よくわかっていません.型推論以下でメモリアレンジメント決定より上のレイヤーの話っぽくて,本当に真面目にやるならglobals.mlの型付けで特殊なことをしないと効果が出ないはずです.具体的には,配列の配列をnull pointer的なArray.make 0 nからなる配列で初期化しており,アクセスのタイミングによっては配列の値に依存してアクセス位置が変わってしまうみたいな感じでした.手で証明するのは簡単ですが,コンパイラ内で検証するのは結構骨の折れる作業です.
コンパイラ最適化
たのしいコンパイラ最適化ですが,限度があって,普通のアーキテクチャ(かつシングルコア)向けでは実行命令数11億(128×128)程度に落ち着くと思われます.実行時間に関しても,大量のload命令を改善しない限りコンパイラができることは少ないはずです.本気で高速化したいならISAをちょっといじるだけではだめで,コアにちゃんと関わりながらアーキテクチャを見直すべきです.なので4人班ならコア係/コンパイラ・コア係/コア・メモリ係/シミュレータ・FPU係,が理想のパーティだと思っています.単位要件は係ごとですが別の係の人に手伝ってもらうのは有効みたいなので,実態がこんな感じでも多分問題ありません.
以下は最終発表のスライドに書いてあった内容です.
効果があったコンパイラ最適化
どのくらい命令数が減ったかとかを計測しなかったので,何がどのくらい効いているのかわかりません.最適化ありきで実装を省略したものもあり,最適化を外して計測するということも難しいです.
CSE
メモリアクセスを減らしたかったのでエイリアス解析も同時に行った.
ループ検知・インライン展開
ループ検知はSSAを意識してphi相当のものを計算すると良い.
インライン展開は命令メモリの許す限り行ったほうが良い. 関数呼び出し規約から解放され, 不要定義除去・定数畳み込みなどその他の最適化に大いにつながる
ループ検知はインライン展開の対象になるIRで行ったほうが良い.
mincaml改造なら KNormal.t
実行に使ったコードは,「600行以内または一度のみ使用される,非再帰関数を展開する」戦略のもの
最適化パスの集中
他の最適化と合わさって爆発的に命令が減る!インライン展開と同じIRで最適化を進めるべき
(2022年度の他のコンパイラ係は,最適化を実行するIRのレイヤーがかなり低めになっている傾向にありました.K正規形がだいぶ素直で扱いやすい形をしているので,悩んだらここの時点で種々の最適化を行ったほうが良いです.)
グローバル変数
関数がキャプチャする変数は,レイトレでは定数と配列のみである.lambda liftingは無意味.
クロージャを完全に消滅させることができるため,クロージャ変換は実装してない
実装としては,値をコンパイル時に計算してdata sectionに配置
ジャンプ短縮
空の基本ブロックへのジャンプ,のような無駄なジャンプの連鎖をできる限り短縮.合流があるので,単につなげるだけでは下手するとプログラムサイズが大きくなる
if式が生成する小さい基本ブロックがどうやら非常に多かったらしく,条件式中のif式とか,thenかelseの片方がunitの場合とかはこの最適化がありえないくらい効く.
余ったレジスタでグローバル変数のレジスタ化
レジスタ割り当てがそこそこ優秀なので,使わないレジスタとか出てくる. 引数用レジスタとかもABI上用意しているが実際使われないことがある
ポインタ取得とかがされない,純粋なload/storeからなるものをレジスタに置く戦略 (実レジスタに対するmem2regみたいなこと)
どれくらい効いたかわからないがメモリアクセスはもとより1割くらい減った. float定数もこれに含まれるが,使用回数(ループかどうかは判定してない←これが良くない)の多い順にレジスタ化をした. intはグローバル変数も定数も全部レジスタ(64個)に乗っかったため, まだ余っている
(レジスタが余ったということは最適な割り当てよりも損をしていることになります.OoOを考えるならround-robinっぽいmincamlデフォルトのレジスタ割り当ての方が良いかもしれません.)
日記
この日記はslackの壁打ちチャンネルの内容から抜粋したものです.CPU実験は90日以上に渡って行われるため,slackを使うのはやめてdiscordにサーバー建てるとかの方が良いです.
見つけたバグについて少しだけ書いてあるけど,コンパイラをスクラッチする人以外はこの手のバグを一切踏まないはずなのであんまり役に立たないと思います.役に立つかどうかでいうとコンパイラをスクラッチしてシミュレータ係を兼任する人なんていないのでそもそも何の役にも立たないか.
10/18ごろ 開始
11/30 パーサー・アセンブラを作った.リンカもどきもできたので下から作っていくことに
12/1 IOとかについて考え始めた
12/2 レジスタ割り当てを考え始めた.同期からレジスタ割り当ての資料をもらい,読んで実装を始める
12/15 活性解析おわり
このへんでレイトレのコンパイルを通そうとし始める
1/3 型推論できた
1/4 コンパイルが通ってしまったためコンパイラのバグ探しを始める.ここから20日間がテストもあり一番つらかった.
1/7ごろ CFGのprogram pointの付け方がずれてたことに気づく.block parameterを導入したせい
1/8 sumがシミュ完動
ネストしたifのバグを発見!LLVMのfront end相当のものをちゃんと書けばよかった
1/9 スタックのアロケート忘れを発見.fibがシミュ完動
1/10 ネストしたifのバグを修正 ifと再帰関数を含む関数がシミュ完動
1/11 デコードを間違えていたことに気づく.特にauipc.auipcを使う必要なくなったので回避
1/12 比較演算のパースが間違ってた
ここからコンパイラのバグが体感全然見つからなくなり,シミュでデバッガを実装して潰すことに.これを1/24まで続ける. Aセメスター始まってからほとんどCPU実験しかしてないからろくに解答用紙を埋められず,余りまくった試験時間中もコンパイラのバグのことを考えていた.
1/14 ようやくレジスタの復帰忘れをしていることに気づく
1/21 flwの引数が大きすぎることが判明,word-addressingにすることで回避
1/24 not->xorの翻訳を間違えたことに気づく.レイトレがシミュ完動!
2/14まで ずっと最適化.1/24までの20日間の苦しさと,以降の20日間の楽しさの落差は忘れられない.知能システム論の単位を落とす
夏休みの宿題を最終日に片付けてるような人間とは思えないほど序盤から頑張ってはいたんですが,それでも兼任とスクラッチは仕事を抱えすぎだったようです.実装しながら最適化を同時に進めていたため最適化にかけた時間は20日よりは多くなっています.ちなみに丸20日よりも多いです.
コア係さんも書いてましたけど,デバッグやデバッグのための工数が必要で最初に書いた表通りになるわけないので,仕事を丁寧に割り振って進めるのではなく,密に連絡を取ってとにかく開発したほうが良いです.
コンパイラ係を志望する方へ
コアはコンパイラを待つので最低限動くものを早めに出せると良いです.mincamlの改造ならISA対応と少しで動かせるので,まずそれはさっさと実装してください.私は動くコンパイラを提出したのが相当遅くなったので全く人のこと言えませんし,特に特定個人を責めているわけではないんですが,コンパイラができないと班員に大きな迷惑がかかります.
多くの人はコンパイラをスクラッチする必要はありません.特殊な最適化を頑張りたいならなおさらしない方が良いです.レギュレーション的に使って良いのかわかりませんけど,LLVM等の既存のコンパイラ基盤を活用してもっと考えるべきことに時間を使ったほうが良いです.必修の単位とかね.
実行命令数削減と実行時間短縮に最も貢献するのはコンパイラ係です.CPU実験で遊びたいならコンパイラ係がおすすめです.よくある最適化を一通り行うだけでも十分命令数を減らせますし,複数の最適化が合わさってさらに最適化が進むこともあり,最適化を行うフェーズに入ってからはだいぶ面白いゲームができます.
私が超えられなかった10億命令の壁を破壊してくれることを期待しています.
シミュレータ係を志望する方へ
コンパイラはシミュレータを待つので最低限動くものを早めに出せると良いです.アセンブラがなくても最悪アセンブリを手書きしてデバッグを進めるべきです.
11月ごろから1月にかけて,シミュレータを実装したら多分やることがなくなるので,班員の仕事をうまく巻き取ってください.
ソフトウェアが普通に書けるなら別に全然難しくないし,単位要件がなんか重くなってることを除けば楽な仕事です.独自のISAならデバッガみたいなものを作ってあげるとコンパイラ係がとても助かります.この学科はまともにプログラムを書ける人がそう多くないので,周りより書ける自信があるなら買って出ましょう.
RustでOCamlのパーサーを書くために
25日目の記事です.
これは1日目の記事 シミュコンパイラ係はやめとけ - f03d-5bab's blog でちょっと言及した話で,先行研究:
の続き,というか1年後の記事です.コンパイラの初めの方の処理の理解が怪しい人は読んできてください.
読みましたか?なんかもう上の記事で結論が出されている感じですが,私の結論は違ったので書きます.
要旨
logosも十分あり- 自由な型を入力できるようなparser generatorは多い
yacc定義のPEG形式への翻訳は,precedenceは簡単でassociativityは(専用の機能がなければ)ちょっと難しいlalrpopはconflictを解消できなくて大変
動機
今回書きたいparserはOCamlのサブセットの言語を入力とするものです.書きたいは嘘だな.もう書いたので書きたくはないです.
ここでは動機づけとしてCPU実験の話をします.1日目の記事で触れたように,CPU実験のコンパイラ係はOCamlのサブセットの言語を入力とするparserを書くことになり(書くことになるわけではなく,自分からこの道を選んでいます(為念)),←こういうネストしたコメントが残念ながらコードに登場してしまいます.どう考えてもネストさせる必要がないものが3箇所だけ*1.だから,ネストしたコメントに対応するparser(lexer)を作りたかったのでした.
実はこの動機づけには不足があり,というのも一体型(文字列から直接構文木を構成するようなもの)になっている多くのパーサジェネレータで,ネストしたコメントに対応するのは簡単だからです.多くのパーサジェネレータは生成規則自身を呼び出すことができ,ocamllex と同じようにコールスタックで実現できます.pegなら次のように書けばよいです.上2つのruleは関係ありません.
peg::parser!(grammar parser() for str { pub rule expr() = ident() _ "+" _ ident() rule ident() -> &'input str = $(quiet!{[c if c.is_ascii_alphabetic()][c if c.is_ascii_alphanumeric()]*}) / expected!("identifier") rule ws() = [' ' | '\t' | '\n']* rule _() = ws() ** ("(*" comment()) rule comment() = [^ '(' | '*']* ( "*)" / "(*" comment() comment() / [_] comment() ) });
"(*"で再入して2回commentを呼んでいるところもocamllexによる標準的な実装と同じですね.ここを1回にするとネストできない版になります.lexerを分離する場合と同じく空白を読み飛ばす部分にコメントを飛ばす処理が混ざってくるため少しだけ非自明な感じですが,C-styleのコメント/* ... */と同じで難しくはないでしょう.(12/29追記:コメントが複数あるものを受け付けない実装になっていたのを修正.)
例の記事のデモも次のように書けます.型定義は例の記事と同じです.
エラー処理は省いていますが明らかな変更のみで対応できます.普段からエラー処理をさぼっているわけではありません.うそじゃないよ
peg::parser!(grammar demo() for str { rule num() -> i64 = s:$(['0'..='9']+) { s.parse().unwrap() } rule ident() -> &'input str = $(quiet!{[c if c.is_ascii_alphabetic()][c if c.is_ascii_alphanumeric()]*}) / expected!("identifier") rule ws() = [' ' | '\t' | '\n']* rule _() = ws() ** ("(*" comment()) rule comment() = [^ '(' | '*']* ( "*)" / "(*" comment() comment() / [_] comment() ) use BinOpKind::*; rule term_op() -> BinOpKind = "+" { Add } / "-" { Sub } rule factor_op() -> BinOpKind = "*" { Mul } / "/" { Div } rule atom() -> Box<Expr<'input>> = "(" _ e:term() _ ")" { e } / l:position!() _ x:num() _ r:position!() { Box::new(Spanned::new(ExprKind::Num(x), (l, r))) } / l:position!() _ i:ident() _ r:position!() { Box::new(Spanned::new(ExprKind::Var(i), (l, r))) } rule term() -> Box<Expr<'input>> = precedence!{ e1:(@) _ op:term_op() _ e2:@ { let l = e1.span.0; let r = e2.span.1; Box::new(Spanned::new(ExprKind::BinOp(op, e1, e2), (l, r))) } -- e1:(@) _ op:factor_op() _ e2:@ { let l = e1.span.0; let r = e2.span.1; Box::new(Spanned::new(ExprKind::BinOp(op, e1, e2), (l, r))) } -- e:atom() { e } } rule stmt() -> Stmt<'input> = l:position!() _ "let" !ident() _ x:ident() _ "=" _ t:term() _ ";" r:position!() { Spanned::new(StmtKind::Let(x, t), (l, r)) } / l:position!() _ "print" !ident() _ t:atom() _ ";" r:position!() { Spanned::new(StmtKind::Print(t), (l, r)) } pub rule program() -> Vec<Stmt<'input>> = stmt()* }); fn main() { demo::program( r#"(* x = 3 *) let (* x = 3 *) (* x = 3 *) x = 1 + 2; let y = x * 4; let z = x + y * x; (* 39 *) print (x + y + z); (* 54 *) let w = z / 3 + y; (* 計算の (* 結果は *) 0 になる *) let ans = x * (y - w) + y; print ans;"#, ) .unwrap(); }
空白を読み飛ばす部分が大量に出てきて鬱陶しいですね.pegは_, __, ___の名前がついたruleを括弧なしで呼べるため薄目で見れば気にな…ります.仕方ない.
じゃあなんでまだパーサーの選定で悩むことがあるかというと,3Sの講義でLR構文解析のアルゴリズムとそれがそこそこ複雑であることを学び,失敗したらバックトラックをする(失敗する前にコピーをする)ような構文解析はLR文法であるところのOCamlに不向きかなと思ったのです.実装して比較する時間すら惜しかったため憶測でしかありません.同じLR法なら文法ファイルの移植も簡単だと踏んでいたという理由もあります(実際は全然そんなことありませんでした.上の例からわかるように,precedence指定されているものだけならPEGで容易に書き換えができ,combineやpegはプログラミング言語で出てくるような文法をparseすることに特化した機能を持っているため,LR法に強いこだわりがなければ全然これらのほうが良いです).
というわけで,コンパイラとしてOCamlのサブセットの文法を入力とし,エラー出力のために位置情報を改行込みで認識したいという前提で,LR法にどれだけ準拠しているかと,nested commentを扱うために行う作業の量の観点から,rustで使えるlexer + parser各ライブラリの比較をします.例えば,入力がバイト列であったり,C-styleのコメントだけで十分だったりする状況なんかは考慮していません.
時間が取れなくて全部は試せていないもののテストやexampleは全部読んでいます.なお実際に実装で用いたのはplexとlalrpopの組み合わせです.
比較
| crate name | version | type |
|---|---|---|
plex |
0.2.5 |
lexer, parser |
logos |
0.12.1 |
lexer |
nom |
7.1.1 |
parser |
combine |
4.6.6 |
parser |
peg |
0.8.1 |
parser |
lalrpop |
0.19.8 |
parser |
この記事がmajor update後に読まれている気が全くしませんが,versionを固定しています.
コンパイラやアセンブラやlinterを作ろうと思った場合は特に,構文木の要素が入力のどの部分から来たのかという情報がほしいです.これを位置情報と呼ぶことにします.構文木の各要素の,対応する入力文字列におけるline numberとcolumn numberのことです.rustcやclippyのあの丁寧なエラー報告も,構文解析時の開始地点と終了地点それぞれのline numberとcolumn numberを全ての要素がずっと持ち続けているからexactな場所に波線を引けるんですね(波線を引いている人は位置情報を受け取ったannotate-snippetsとかrust-analyzerだけど).今回は文字のbyte offsetだけだと困ります.人間には改行文字が特別な形で見えているため.後から改行文字を数えるのはなんか気に入らないので,それを踏まえるとplexくらい自由度があるとよさそうです.
文法の記述をどこに行うかは意外と重要で,lexerについてはlogosもplexも.rsに書けるので大差なく,parserについてはpegに軍配が上がります.人間よりIDEに考えてもらったほうが変なミスが少ないですからね.
lexerとparserで分けてはいますが,parserが正規表現に近いことしかしないなら機能としてはlexerなんですよね(ここでparserとして紹介しているものをlexerとして用いることができるということです.文字列からVecなどに入ったトークン列を構成する,.lexと似たような非常に単純なparserを作る(ライブラリを使わないほうが簡単に書けそうだけど)).なので,lexerの選択肢が極端に少ないということはなく,問題はlalrpopとpeg,nom,combineくらいしか入力に(ほぼ)任意の型を取れない点にあります.あれ,意外と多いじゃん
lexer
全体の比較はこれくらいにして,まずはlexerからそれぞれの特徴を見てみます.
plex
「次の文字列」を読んでユーザー定義の型を返すというインターフェースが用意されます.任意の型Tokenに対し,次のように書き,
lexer! { fn next_token(text: 'input) -> Token; /* ここにruleを書く */ }
次のシグネチャを持つグローバル関数定義が出力されます.Tokenは当然(←w)'inputに依存できます.
fn next_token<'input>(input: &'input str) -> Option<(Token, &'input str)>;
「次の文字列」というのはこの関数の入力の先頭からの文字列のことです.何らかにマッチしたらその文字分進んだ&'input strが一緒に帰ってくるので,それを適当な構造体で持ち回してIteratorとかを実装するのが主な使い方です.Tokenとしてトークンではなく制御パターン(とその中身にトークン)を持つようにすると,簡単にDFAなどを構成できます.実装量は少し多めだけど,マクロの箱の中身が単純であり,インターフェースが入力とほぼ乖離しないところがだいぶ素朴で扱いやすい.
nested commentには,例の記事で実装が示されていたように,コメントの内部とそれ以外の2種類のlexer!を用いて,後者に制御のための構造をはさむことで対応できます.
位置情報は,改行のたびに現在位置を適切に更新し,文字列を読んだ際に残りの文字列に対して.chars().count()をした結果を覚えておき,消費された文字数を計算すると計算回数が減らせます.こういう感じです
pub struct Lexer<'input> { remain: &'input str, last_remain_len: usize, current_loc: Loc, } // in next(): let state = next_token(self.remain); let (state, remaining) = state?; self.remain = remaining; let remain_len = remaining.chars().count(); let consumed = self.last_remain_len - remain_len; self.last_remain_len = remain_len; let lo = self.current_loc; self.current_loc.col += consumed; let hi = self.current_loc; // ...
ルールの右辺は<syn::Expr as syn::parse::Parse>::parseで処理される部分につき,rust-analyzerによる補完が効きます.
logos
トークンを一つのenumで表す(これをenum Tokenとします)ことを前提にし,derive(logos::Logos)を生やしてTokenの各メンバのattributeに&strからの対応を書くようです.一つのメンバにつき複数の対応を書くことができ,クロージャをその場で書けたり関数を呼べたりするみたいです.attributeの内部に書くのはrust-analyzerが何も言ってくれないので微妙そう.pure rustで書いた関数を呼べる上に戻り値の型で簡単に制御を表せる点はとても良いですね.callbackの戻り値はenumに包まれていないのでテストも分離しやすい.
Tokenのメンバについたattributeについて,入力を読んで正規表現とのマッチに成功した際に実行されるクロージャや関数は,lex: &mut logos::Lexer<Token>を引数にとり,マッチした文字列はlex.slice()により獲得します.
nested commentに対応するには,plexで考えた実装と同じようなことをすればよいです.2つのenumにLogosを生やして,コメントの開始のcallbackでlogos::Lexer::remainder(&self)(lex.slice()より後の文字列を返す)とかlogos::Lexer::bump(&mut self, n: usize)(n文字進める)を呼んでいい感じにします.コメントを飛ばす処理はスクラッチした方が簡単だと思います.
位置情報はbyte posしか取れないみたいです.
速いことは確かなようで,lookup tableとかを自分で実装する手間もないため,単純な字句解析がしたいならこれで十分そうです.使い方を知るのが大変寄り.
parser as lexer
parser generatorにlexerを生成させることを考えます.可能というだけで効率が良いわけでは決してなさそうなので軽く.nested commentは違いますけど,正規言語の範囲ならふつうバックトラックが不要なのでpegやcombineでも本領発揮できるはずで,nomのように入力をバケツリレーするとかえってわかりにくくなりそうなものです.この話おわり.logosかplex使おう.
parser
nom
現行のversion 7はコンビネータもしっかりサポートされており,だいぶcombineに似ているというか仕事を奪っている感じです.今回は関係ないけどstreamingに対応しているのが偉い.
parserの役割を担うのはnom::Parser<I, O, E>を実装する型であり,このtraitのfn parse(&mut self, input: I) -> nom::IResult<I, O, E>がparseを行います.IResultはpub type IResult<I, O, E = Error<I>> = Result<(I, O), nom::Err<E>>;のことで,
nomの長所である,Iが&[u8]や&strであるparserが多いということが入力の型を任意にしようとすると活かせません.それでもandやorはnom::Parserにくっついているのでそんな不自由することでもないし,トークンに対するパターンマッチを実行するのも容易です.
pomはnomの下位互換だと思うので紹介しません.
combine
parsecを元にしているだけあってトレイトが重く使われており,入力もそんな感じです.
parserの役割を担うのはcombine::Parser<Input: combine::Stream>を実装する型であり,このtraitのfn parse(&mut self, input: Input) -> Result<(Self::Output, Input), <Input as StreamOnce>::Error>がparseを行います.combine::Streamはpub trait Stream: combine::StreamOnce + combine::stream::ResetStream + combine::Positioned { }であり,特にcombine::StreamOnceでSelf::Token: Cloneが課せられています.提供されている実装は&strとimpl<'a, T> StreamOnce for &'a [T] where T: Clone + PartialEq (と&mut版)に対してで,一応そこそこ自由な入力ができることがわかります.もちろんpub traitなので実装もできます.
入力の型を変えるとコンビネータしか使えなくなるのはnomと同じで,違うのはResult::<T, E>のTのタプルの順と,しれっと付いているToken: Cloneです.トークン列のスライスを入力にすればいいだけですけど,attemptを頻繁に使いたいような場合,選ぶならnomでしょうか.
try operatorはいいですね.やっぱりparsecが書きやすく読みやすいのはコンビネータ中心であることよりdo記法に依るところが大きいと思います.使うことに関してのモナドはみんなそうか.
peg
入力に&[T] where T: Copyを選べます.正確にはruleで用いる機能ごとにpeg::ParseElem(パターンマッチ), peg::ParseLiteral(リテラル(これはlalrpopに似ている)), peg::ParseSlice(マッチする入力のスライスを返す)の3つのtraitがあり,それぞれを実装するものがその機能を利用できます.使わない機能のtraitを実装しないことができます.T: 'input + Copyに対して[T]へのこれらのtraitがすでにimplされています.T: Copyは次のように参照を渡せばトークンの型には要求されません.
ParseElemにrustのpatの文法が利用できます.charに対してパターンマッチというと聞こえが悪いですが,後置ifが使えるんですよね.
位置情報の取得は,規則で得た値の束縛と同じように行います.position!()をrule名が来る場所で使うとpeg::Parse::PositionReprが束縛できます.トークン列の型Tokens: Parseに対し<Tokens as peg::Parse>::position_repr(&'input self, p: usize)を呼んでいるということです.
入力が正しい場合,rust-analyzerのsemantic highlightingがいい感じに効きます.規則にマッチした後実行されるコード部分の{,}内とruleの引数の(,)内は直のproc_macro2::TokenStreamなので補完も効きます.ruleの名前をそのまま関数名に使ってくれていないようで,go to definitionできないのが少しだけ残念.かなり気に入っています.
pestはpegの下位互換だと思うので紹介しません.
plex
plexもparserを作れます.入力は自由なenumにできるみたいですね.crate lalrが提供するLALR(1)状態の構成を使っているようで,そこでconflictが見つかるとエラーとするようです.lalrはpriority(?)が同一なreduce/reduce conflictと,全てのshift/reduce conflictをconflictとして報告します.precedenceとassociativityを反映する機能はなさそうでした.lalrpopの下位互換です.
lalrpop
lalrpopが入力とするのは,Writing a custom lexerに記載のある通り,pub type Spanned<Tok, Loc, Error> = Result<(Loc, Tok, Loc), Error>;をItemとするIterator<Item>です.ここでTok, Loc, Errorはユーザー定義の型であり,Loc: Clone以外のtrait制約はありません.
文法は.lalrpopという拡張子のファイルに保存します.grammar<'input>;としておくと必要な箇所全てでこのライフタイムが使えるようになるため,TokやErrorが入力のライフタイムを持ち越せます.ちなみにclippyするとここまで紹介した機能でめっちゃ警告がでます.codegen部に#[allow()]差し込むだけでいいのに.
位置情報の取得は,規則で得た値の束縛と同じように行います.@Lや@Rを文法名が来る場所で使うとそれぞれ最左,最右の要素の左,右の位置が束縛できます.
名前に反してLR法を謳っており(LALRに弱めることはできる),まだ(2年間も)ドキュメント化されていないものの生成規則のprecedenceとassociativityを自動で解決する例の機能*2はあるのに,shift/reduce conflict, reduce/reduce conflictの解消方法を持たないんです.yaccはprecedenceとassociativityを指定することにより次の規則に従って勝手にreduceとshiftを選択してくれますが,lalrpopにはそれができません..yの中身をただ置き換えるだけで動かないということに気づいたのがこれを選んで翻訳を終えた後で,結構ショックでした.目立つ場所に書いておいてほしい.うちではconflict解消やってません,って.
- If there is a shift-reduce conflict and both the grammar rule and the input character have precedence and associativity associated with them, then the conflict is resolved in favor of the action -- shift or reduce -- associated with the higher precedence. If precedences are equal, then associativity is used. Left associative implies reduce; right associative implies shift; nonassociating implies error.
https://docs.oracle.com/cd/E19504-01/802-5880/6i9k05dh3/index.html
dangling ifのshift/reduce conflict解消ですら難しいのに,OCamlくらいの規模の文法で発生するconflictを解消するのがかなり骨の折れる作業で,これにかなり時間を持っていかれた記憶があります.次からは絶対pegの方使う.yaccの現代的なrust portとして十分輝けるだけに惜しいです.役割として被っていそうな,最近出てきたlrparはこれを読む限りreduce/reduce conflictを教えることはできるみたいです.yaccとの互換性がほしいならこっちを使ったほうがよさげ.
結び
この記事はこれで終わりです.実装の章がないので短めですね.
あ,ぼっち・ざ・ろっく!は観てくださいね.最高のアニメでした.
ISer Advent Calendar 2022に記事を書いてくれた21er, 22er, 23erの方々,ありがとうございました!
*1:え?そんなにネストしたコメントが嫌なら字句解析の前に処理すればよいのでは,だって?そうですね.それをCPU実験の担当者がコードを配布する前にしてくれればよかったんですけどね(カウンター).今度交渉してみます.
12/25
22日目の記事です.24日に読むことを想定しています.
12月24日から12月25日といえば?
そう,ぼっち・ざ・ろっく!1期12話の放送日(12/24 24:00~)ですね.観てください.本当に面白いです.
◢◤WEB予告公開◢◤
— TVアニメ「ぼっち・ざ・ろっく!」公式 (@BTR_anime) 2022年12月23日
第12話「君に朝が降る」
バンドを組み様々な人に出会い、今までひとりでは見えなかった景色がそこには広がっていた。いよいよ結束バンド4人の文化祭ライブが始まる。
📅12/24㈯ 24:00~
📺TOKYO MXほかにて放送開始
🔗URLはこちらhttps://t.co/WDtXvFcsuO#ぼっち・ざ・ろっく pic.twitter.com/ShWKZxbwc6
Abemaではその前に1話から11話までの放送もあるので,この機会に最新話まで追いつくことができます.すごい!観るしかない!
/
— ABEMAアニメ(アベマ) (@Anime_ABEMA) 2022年12月23日
いよいよ明日🎸
「#ぼっち・ざ・ろっく!」
ABEMA ROCK(6HSP) 放送📣
⏩https://t.co/mEChVzqeaa
\
キャスト大集合の生放送特番に加え
特番前は1~10話の一挙放送📺や
特番後は最終話を【地上波同時・独占先行】放送📡も
画像でタイムテーブルをチェック⏰@BTR_anime pic.twitter.com/SXEVZTqp2Q

下北沢駅の最終回広告は見に行かれましたか?私は行きました
◢◤下北沢駅広告掲出◢◤
— TVアニメ「ぼっち・ざ・ろっく!」公式 (@BTR_anime) 2022年12月19日
「#ぼっち・ざ・ろっく!」
最終回広告を下北沢駅に展開中🎸
◆12月19日㈪~12月25日㈰
📍小田急 下北沢駅 エスカレーター壁面
📍京王 下北沢駅 エスカレーター・階段壁面
※駅及び、駅係員へのお問合せはご遠慮ください。 pic.twitter.com/2APO54jbvq
秋葉原駅にはBD1巻の広告が出ています.だいぶ前に予約してるので,12話を観てから2周目を予約するか決めようと思います.
˗ˏˋ 掲出情報 ˎˊ˗
— TVアニメ「ぼっち・ざ・ろっく!」公式 (@BTR_anime) 2022年12月19日
「ぼっち・ざ・ろっく!」
Blu-ray&DVD Vol1の広告が、
下記のサイネージで掲出中です🎸
📍JR秋葉原駅電気街口:12/19~12/25
※駅・係員へのお問い合わせはご遠慮ください。#ぼっち・ざ・ろっく pic.twitter.com/fWhcUv8H1g
12月28日はBD1巻とアルバム「結束バンド」の発売日です.アルバムは12月25日から先行配信があります.
原作コミックスときららMAXもよろしくお願いします.売れすぎててなかなか布教用に手を出せずにいます.地下に置きたいです.
シミュコンパイラ係はやめとけ
シミュコンパイラ係はやめとけ 何の話?CPU実験です
明日はもうひとりの二係兼任であるコアFPUメモリ係さんの記事です.
22erのみなさんCPU実験の記事で1日分埋められますよ(CPU実験の詳細は他の方に譲ります).そういう伝統の必修科目がこの学科にはあって,分野的にも仕事の内容的にも大きく分けて4つの仕事があります.となると当然4人でその仕事を分担しますよね.なんで班分けのアンケート*1に3人班でも良いかどうかも聞くラジオボタンがあるんでしょうか.ああ,生徒数が4の倍数でない場合がありますもんね.間違っても選択肢の存在の面白さとかで選ばれるようなものではないですね.
3人班は4人分の仕事をなんとかしてこなすことになります.あろうことか3人班を希望すると班分けがより円滑に進み,見事3人班に割り当てられることができます.できました.これは,班分けのアンケートで「3人班を希望」し,第一志望にコンパイラ,第二志望にシミュレータを選んだハードウェアわからない人と同じ班になった,そんな選択肢は選んでない上に第一志望がこの二つのどちらでもない二人に二人分の仕事を押し付けるわけにもいかず,二つの係を持つことにした人の記事です.
あ,そうだ ぼっち・ざ・ろっくを観てください こんな記事読んでる場合じゃないですよ
CPU実験を経験した21erから各係の詳細について聞いて,アンケート期限最終日までコンパイラとシミュレータのどちらを第一志望にするか悩んでいたので,両方やれたのはよかったです.コンパイラ・アセンブラ・リンカ・シミュレータなどを,rustcなどの既存の実装を学びながら苦しんで実装する機会をもらったのもよかったんですが,結構頑張っている割に終わる気配が見えなくて2ヶ月くらいずっと絶望しています.10月頭には11月中完動の予定を立ててたのに.いま線表見たら発狂しそうだから見ません.まだレジスタ割り当てが書き終わらないです.対面授業が始まってしまったこともあって,睡眠時間を削って苦痛と向き合っていたら体調を崩したし,気持ちだけではどうにもならない感じになってきました.レジスタ割り当てよりも喜多郁代の家族構成の方が知りたいし,mincamlのコード汚すぎてもう読みたくないし,気持ちもどうにもならない感じになっています.シスプロイヤイヤ期の3Sより苦しんでいる.
私はOCamlが嫌いなのでRustでコンパイラを書き直すことになりました.いや,しました.OCamlが嫌いでも流用することはできます.つまり逆張りです.OCamlにはそこそこまともなLR法のパーサジェネレータocamlyacc(, menhir)がある一方でRustにはなく*2,このあたりの選定と実装やってたら3週間くらい経ってました.シミュレータ係でもあるのでシミュレータとアセンブラ作り3週間くらい経ち,体調を崩しながら地道にコンパイラ作ってたらまた3週間くらい経ってました.今週が第10週目です.もうシミュ完動する班が2つほど現れはじめて,火曜の発表会で肩身が狭いどころではなくなってきました.去年のアドカレで読んだコンパイラ係の記事よりだいぶ遅くない?うちの班が一番完動遅かったら申し訳なさでどうにかなりそう,来週も休もうかな.
なんの話だっけ.そう,mincamlを翻訳しているんですけど(mincaml特有の仕様により実装で楽ができる部分もあるので),すでにRustに翻訳されているものがただの逐語訳になっていて全然使えないので,結局自分で読むことになっています.クロージャ変換まではわりと単純で読みやすくて翻訳もいいペースで進んでいたのに,レジスタ割り当て付近はだいぶ煩雑というか雑でとても読めたもんじゃないです.来年からコンパイラ書き直す人はクロージャ変換より後は一から実装した方が良いですよ.というか,コメントに(* super-tenuki *)とか書いてある,開発が活発じゃない14年前のソフトウェアを触ることになるのおかしいだろ.おかしくないかなぁ.
並行して行われる*3コンパイラ実験は,最初の方でmincamlの理解につながる内容だけでなくコンパイラを作る上でごく基本的なことも講義中に話しており,第6回目までにコンパイラをスクラッチするにはちょうどいい機会のような気もします.いや,そんなことないか.コンパイラが動かないとアセンブリを手書きすることになるし,レイトレのコードを渡してコア係さんたちに勝手に進めてもらうこともできないので,コンパイラを自作するなら2ndでやったほうがいいと思います.
もう書けることなくなってきた.実はコンパイラのスクラッチとシミュコンパイラ係と無能を両立させようとすることに問題があるのかもしれない.タイトル詐欺です.選べるなら1つにした方がいいですね.あとコア係の人にコンパイラ実験の課題を任せるのもやめたほうがいいです.ごめんなさい.あと中途半端な理由でこの学科に来ないほうがいいです.ごめんなさい.なんか悲しくなってきたな.アドカレ立てるの遅すぎる上に初日から思いっきり遅刻してすみません.対面授業に出ているぼっちちゃんの方が私よりずっとずっと偉いよね.結局コンパイラとシミュどっちもやりたい!コンパイラスクラッチしたい!というわがままを聞いてもらって勝手に苦しんでいるだけなので自業自得です.すみませんでした.
今日木曜か,明日提出の計算量理論演習もやらないと…
レポートを書こう
これは ISer Advent Calendar 2021 の18日目の記事です.
理学部情報科学科に所属しているのに紙のレポートを提出しているんですか?まさかね.
今回は私のレポート執筆環境の紹介です.全知の方向けに端的に言うと,「markdownを書き,pandocでfilterを適用しつつ.texに変換し,LuaLaTeXでコンパイルするフローを変更監視付きで行う」をしています.以下はそれぞれの技術についての詳細です.
Markdown
HTMLを簡単に書ける言語,もとい,文書の構造を少ない記号とインデントだけで表現できる言語です.装飾部分を意識せずに文書を書けるように,文法で制限していると考えるとmarkdownで書く意義が伝わると思います.
ここでは,たくさんあることで有名なMarkdownの方言のうち,markdown.plではなくpandocが認識するPandoc’s Markdownを扱います.レポートではこれを書きます.
LaTeX
出題されるレポートの内容上,数式が多く,また複雑になる上に,レイアウトにはそこまでこだわらなくてよいので,組版1自体はLaTeXで行うことにします.LaTeXは皆さんご存知2だと思うので説明は省きます.
レポートではこれを極力書きません.最悪処理系TeXに依存したコードを書きたくないので.
Pandoc
Pandocはマークアップ言語間で文書を変換するフリーウェアです.重要なことはすべてマニュアルに書いてある.
Pandoc is a Haskell library for converting from one markup format to another, and a command-line tool that uses this library.
この"converting"は,それぞれの言語間に特殊な変換を施しているのではなく,pandoc独自の中間表現(Pandoc AST)を経由して実現されます.入力言語からASTへの変換をreader,ASTから出力言語への変換をwriterと呼びます.
Pandoc is structured as a set of readers, which translate various input formats into an abstract syntax tree (the Pandoc AST) representing a structured document, and a set of writers, which render this AST into various output formats. Pictorially:
[input format] ==reader==> [Pandoc AST] ==writer==> [output format]This architecture allows pandoc to perform
×
conversions with
https://pandoc.org/using-the-pandoc-api.html
この記事では入力言語としてmarkdownを選択し,出力言語としてlatexやpdfを選択することを想定します.
他にもhtmlやdocxなどに対応しており,後述のfilterも活用することで様々な用途で活用できます.
Readerやwriterを自分で作ることもできますが,この記事ではそこまで触れません.
Install
Pandoc - Installing pandocに書いてあります.最新版を入れるのがまあまあめんどくさいですし,後述のfilterで他のなんらかの環境を一緒に入れることになると思うので,Dockerを使いましょう.公式imageをFROMしたり,COPY --from=の対象にして/usr/local/bin/の関連ファイルをコピーしたりすれば動きます.
私と実験のグループが一緒になってしまった被害者さんたちにはもうDockerをinstallしてもらっていますし,堂々とDockerを登場させられますね.
Pandoc’s Markdown
Pandocは,markdownの様々な方言にわたってそれぞれの文法を一つずつ拡張機能と捉え,拡張機能の特定の集まりをデフォルト(pandoc’s markdown)とし,拡張機能単位で有効化/無効化することが可能です.
これも全部ここに書いてあります.優秀なドキュメント.
https://pandoc.org/MANUAL.html#pandocs-markdown
PDF Output
Pandocの出力言語にpdfを選択すると,pdf-engineで指定されたプログラムを用いてコンパイルを行います.
それに渡されるオプションはpdf-engine-optで渡します.
Default File
コマンドラインオプションが与えられなかった場合のフォールバックを指定できます.いちいち長いコマンドを書かずに設定ファイル化できるので,使わない手はありません.
https://pandoc.org/MANUAL.html#default-files
実体はただのyamlです.ここで定義したオブジェクトのうち,variablesの中身がそのまま定義済み変数となり,template内で参照できます.
Template
-s(--standalone)を引数に含む場合,そのwriterの言語の処理系で自己完結するファイルを生成するようにできます.これを指定しなかった場合との差異を埋めるのがtemplateです.
デフォルトのtemplateは
pandoc -D latex
によりstdoutに書かれます.
Templateは,プリアンブルに書かなければならないものにも使えます.例えば\usepackage{}とか\tcbuselibrary{most}みたいなものの有無や順序,引数などを適当に変数リストから拾ってtemplateで条件分岐することで実現できます.
私はLuaLaTeXのデフォルトの数式フォントが好きではないので,
\setmathfont{Latin Modern Math} \setmathfont{TeX Gyre Pagella Math}[range={bb,bbit}, Scale=MatchUppercase] \setmathfont[range=\setminus]{Xits Math}
こういうのも追記しています.3行目はLatin Modern Mathに無い\setminusを適当なところから借りるものです.
Filter
Pandocの変換過程でPandoc ASTを経由することにさっき触れました.Pandoc ASTをPandoc ASTに変換する関数があれば,文書構造だけを見て別の構造を変換できます.それがpandoc filterです.合成に関して単位的半群なのでいくらでも適用できます.
https://pandoc.org/filters.html
Filterは任意の言語で書くことができます.AST上の値がadjacently taggedなjsonになってstdoutに流されるので,それを歩けば良いです.HaskellやLuaなど一部の言語では,AST上の値に対する関数を書くだけでfilterの機能をするようにサポートされています.
公式の例(残念ながらpython)が割と網羅的で良い感じです.pythonを使うならpanfluteを使うとpandocfiltersライブラリよりも意味が取りやすいコードが書けるらしいです.
上のページやリポジトリからもわかるように,filterの用途は多岐にわたります.他のプログラムの入力をfenced_code_blocksに書き,出力を埋め込むという使い方が特に有効で,当環境でも頻繁に用いています.
Crossref
数式を文書内で参照するような場合,crossrefの機能でラベル付けしたものを参照すると,自動で番号が振られます.これもfilterです.ただ,これは独自のAST上の型を持っているわけではなく,直にstringを書き換えるものなので,filterを適用するとラベルの情報は消えます.
引用が生じるほど構成がごちゃごちゃしたレポートを書きたくないので,最近の私は使っていません.
Citeproc
論文を引用したくなることがあります.citeprocオプションを使うと適切な形式で引用ができます.
citeprocはbuilt-inなfilterとして実装されているので,他のfilterとの順を扱う場合はciteprocをオプションではなくfilterとして渡します.
cite-methodオプションはlatex出力にのみ有効であり,これにbiblatexを指定すると,hyperrefの\autorefにより引用し,末尾に\printbibliographyをするようになります.cleverefを使いたかったらfilterを書きましょう.
biblatexでコンパイルする場合,texファイルを複数回コンパイルする必要があるのでした.
to: pdf pdf-engine: lualatex
は1度しかコンパイルを発火しないので,このような場合にはこれは使えず,texファイルをlatexmkの類でコンパイルすることになります.このような事情もあって,pdf-engineにコンパイルを任せきっていません.
VSCode
definition_listsのような,よくあるmarkdownに無いような文法を含んでおり,VS Codeに標準で備わっているsyntax highlightの不足を補う必要3が出てきます.重要なことはここに.
Syntax highlightを提供するには,addonのcontributeにTextMate文法の定義ファイルを与えます.
その実体(yamlなど)は機械的に生成できるため,MSが開発しているmarkdownのsyntax highlightのリポジトリと同じように,ある程度出力を自動化すると楽です.
TextMate文法は公式のreferenceがあり,他のsyntax highlightを提供するコードからも学ぶことができます.
Environment
これらを用いた最終的な環境について簡単に書きます.
拡張機能も作ったのでエディタはVS Codeです.Syntax highlightだけならAtomとかでも使えるんでしょうけど.
LuaLaTeXとpandocとluaの処理系を共存させたいので,適当なdocker containerを建てており,書いたレポートはdockerのマウントによりコンテナと入出力しています.
変更の監視は,手癖でnode.jsのchokidarインスタンスの.on('change',にpandocコマンドを走らせるexec()を置いています.
pandocの起動引数にはデフォルトファイルを渡しており,その中に大勢の変数をくっつけています.文書のメタデータからは改変したlatex用のtemplateや,bibliographyに値を渡しています.
他のメタデータとして,LaTeXの対応マクロに変換されるtitleとauthorを与えています.
メタデータ以外のmarkdownの部分は,普通のmarkdownの文法に加え,pipe_tables,definition_lists,footnotesとinline_notes,fenced_code_blocksなどを用いて書きます.数式はLaTeXに変換される自作の言語のparserとfilterを使ってtex_math_dollarsに,命題や証明の枠はdivをLaTeXの定理環境に変換するfilterを使ってfenced_divsに,オートマトンとか構文木を書くときはgraphvizをfilter化したものを使って,クラス名を与えたfenced_code_blocksに,構造式もopenbabelをfilter化したものを使い,引用はciteprocを使うので,Zoteroに文献を追加し.bibファイルのパスをbibliographyに渡します.こう見るとほとんどfilterでできているような気がしてきますね.
どうしても生のLaTeXを書く必要があるときはraw_attributeで書きます.
おわり
Pandocとpandoc filterで生活を豊かにする記事でした.明日の記事誰か書いてください.
-
LaTeXでレポートを書いている,という人はそこそこいるものの,モダンな仕様や便利なpackageを追えている人はそう多くないですよね.まだplatexでコンパイルしていたり,
\newcommand,{\bf },eqnarrayを使っていたり,偏微分をいちいち\partialを使って書いていたりしてませんよね.bxjs系記事,unicode-mathなどをLuaLaTeX/XeLaTeX上で使えてますよね.↩ -
数式にハイライトを入れたくて拡張機能を作った数日後に
June 2021 (version 1.58)が出て,時間がだいぶ無駄になったどころかファイルの関連付けの上書きまでされたという経験があります.あとvscodeがあんまりエラーを吐いてくれなくてつらい.↩
オンゲキ譜面研究部
これは ISer Advent Calendar 2021 の4日目の記事です.
オンゲキという音楽ゲームをご存知でしょうか?私は知っています.
まず,オンゲキの筐体が設置してある場所に行きます.筐体に100円硬貨を少なくとも1枚投入することによりクレジットが増え,これをゲーム開始時にゲーム内通貨(GP)に変換することでチャプター・曲・難易度選択画面に遷移します.ここで選択した曲と難易度に応じたGPを消費して,演奏が始まります.演奏が始まると,選択した曲と,それに合わせて作られた譜面が流れ始めます.
以下はこの演奏についての話です.演奏において,テクニカルスコア1010000点(最大値)を獲得することと,譜面にはどのようなものが存在するのか分類することがこの記事の目的です.実際の譜面での出現箇所を引用しておくので,動画サイトで譜面を見たり,ゲームセンターで遊んだりすると何を言っているのかわかると思います.
譜面と仕様
オンゲキの譜面には,他の音楽ゲームにも見られるノーツだけでなく,よく知られたシューティングゲームのような要素が混じっています.一見すると曲に合わせてボタンを押しつつ,敵の攻撃を回避する必要があるように思えるこのゲームは,実は多くの状況においてそうではなく,音楽ゲームとして説明できます.
譜面を構成する要素の中で,演奏に関わるものは以下の5*2+3+2つです:
- L-SIDE TAP
- L-SIDE HOLD
- Red TAP
- Red HOLD
- Green TAP
- Green HOLD
- Blue TAP
- Blue HOLD
- R-SIDE TAP
R-SIDE HOLD
BELL
- 敵の攻撃
FLICK
フィールド
- ガードレール
上の10個による組み合わせをこの記事ではなどと書きます.譜面のどこに落ちてくるかはここでは考えません.
色付きの補助線のようなもの(レーン)が譜面に置いてあることがあります.対応した色のTAPがそこに降ってくることが期待されるため,これは操作の誘導に用いられます.難易度 EXPERT, MASTER, LUNATICでは絵や文字の装飾用途1にされることもあります.このレーンはなくてもTAP等の判定には影響しない2ためここには含めません.
TAPが光っていることもありますが,最近の譜面では音合わせにしか用いられなくなってきているためここには含めません.
L-SIDEとR-SIDEの両方を壁と呼ぶことがあります.
各時刻において,壁それぞれについてTAPとHOLDの始点が1個,壁以外のTAPと壁以外のHOLDの始点と2個,BELLと敵の攻撃とFLICKが任意個出現できるとし,演奏時間からこれらの要素への集まりを譜面と定義します.
TAPは判定ラインに重なったときに対応する色のボタンを押すことによって処理できます. Red, Green, Blueに関しては対応する色のボタンが左右2つづつ存在していて,そのうち少なくとも1つがTAPの判定時に押下されることが判定の条件になります. HOLDは,始点がTAPと同じ判定で,始点から終点までBPMに応じた間隔で始点のTAP以降にボタンが押されているかの判定があります.終点で離す必要はありません.TAPと同様,Red, Green, Blueに関しては左右どちらも判定の対象です.始点で押したものを終点まで押し続ければHOLDの判定としては当然良いのですが,HOLDの始点が同時に2つある場合や,HOLDの始点から終点までに同色の別のHOLDが出現している場合があって,その場合には操作を簡単にすることができるどころか,それを暗黙のうちに要求する実際の譜面も存在します(後述).よってHOLDの説明をこのようにしています.
レバーを操作することで,自機の位置を動かすことができます.ただし,ガードレールがついている場合はガードレールを超えて移動することはできません3.ガードレールが出現するより前にガードレールの外にいた場合は影響がありません.
自機がBELLにある程度近ければBELLを取得することができます.自機が敵の攻撃にある程度近ければ敵の攻撃を受けます.敵の攻撃には見た目上様々な種類があります.
FLICKは,その空間的幅に自機が存在し,かつそれと同じ方向にレバーがある角速度以上で動いているかという判定になります.判定の時間的幅は結構広くとられているため,luna blu (LUNATIC)32~35ノーツ目,2596~2600ノーツ目のようなものも可能です.
BELLと敵の攻撃はレバーを動かさずに取れることがあったのに対し,FLICKはレバーを動かす必要があります.
また,フィールド上に自機がいない間TAP,FLICK判定がMISSになります.
テクニカルスコア1010000点の条件は,すべてのTAP,HOLD,FLICK判定でCB(CRITICAL BREAK,最もよい判定)を出し,すべてのBELLを回収し,すべての敵の攻撃を回避することです.
操作
上記のように譜面全体を定義しましたが,例えばや
のようなものは実際の譜面には(今の所)含まれていません.手を動かして見るとこのような配置は不可能であることがわかります.これらが操作できないことにより実際の譜面に含まれていないのだとすれば,どのようなものが操作可能なのか,操作可能なものは実際の譜面に含まれているのかが気になります.
筐体が受理可能な操作
筐体が受理可能な変数は,譜面と仕様の節で述べたように,各時刻における48個のボタン入力と,レバーの座標,角速度です. 他にはL-MENUやR-MENUが存在しているものの,これらは演奏においては(現状)使いません.押したらエフェクトがかかりそうなものですけど.
人間が実現可能な操作
人間は手でボタンを押したり,レバーを持つことができます.ただし,手にはまあまあな制約があり,そのうち左手では,ある時刻において以下の操作のうち一つができると考えられます:
- (L-1) L-SIDEを押す/押し続ける
- (L-2) L-Red, L-Green, L-Blueの単一または複合を同時に押す/押し続ける
- (L-3) L-Red, L-Green, L-Blueの単一または複合を押しながら,押されていないものを押す/押し続ける
- (L-4) L-SIDEを押す/押し続ける
(L-5) R-SIDEとR-Blueを同時に押す/押し続ける
(L-6) レバーを右に倒す
- (L-7) レバーを持って操作する
- (L-8) レバーを持って操作しながらL-Blueを押す/押し続ける
- (L-9) L-Blueを押しながらレバーを右に倒す
(L-2)を実現するための指の配置はいくつかあります.(L-2),(L-5)で使った同時とは,全く同じ時刻でなくとも間隔が短ければ5ここに含むこととします. (L-4)は出張と呼ばれることがあります. (L-5)はやってみればできて,親指でL-Red,残りでL-SIDEを押すことができますよね. (L-8)と(L-9)が難解です.レバーを持った状態で,手を鉛直方向に下ろせば手首でL-Blueを押せないこともないですし,L-Blueを親指で押しながら手を広げて時計回りに回転させるとレバーを倒せないこともないです.
左手で右側の3色を押すこともできるとはいえ,左右の入力に差異はない上に,次節HOLDの乗り換えを用いれば必要なくなります.
これらを時間的に組み合わせることを考えると,別の制約が出てきます.同色のボタンを短い時間で連打することはできず,bpm200なら16分2打程度,bpm150なら16分4打程度,bpm120なら16分8打程度までしか連続できません. (L-2)だけの時間的組み合わせは他の音楽ゲームと同様,階段やトリルを行うことができます.(L-6)は(L-7)よりも準備にかかる時間が短いため,異なる操作として数える意味があります.
右手の方も書いておきます.
- (R-1) R-SIDEを押す/押し続ける
- (R-2) R-Red, R-Green, R-Blueの単一または複合を同時に押す/押し続ける
- (R-3) R-Red, R-Green, R-Blueの単一または複合を押しながら,押されていないものを押す/押し続ける
- (R-4) L-SIDEを押す/押し続ける
(R-5) R-SIDEとR-Blueを同時に押す/押し続ける
(R-6) レバーを左に倒す
- (R-7) レバーを持って操作する
- (R-8) レバーを持って操作しながらR-Redを押す/押し続ける
- (R-9) R-Redを押しながらレバーを右に倒す
左右合わせて,これらの組み合わせにより可能な譜面パターンをいくつか見ます.別の操作を用いて表現できるような操作が多数あるという点がオンゲキの運指の多様性を生み出しています.
(L-6)または(R-6)
ノーツ処理中にフィールドから離れないように自機を操作することと,ベルを回収しにゆくことと,敵弾を避けることのすべてが含まれています.これに(L/R-2)または(L/R-3)を混ぜたものもよく見られます.
(L-1)(R-1), (L-1)(R-2), (L-2)(R-1), (L-2)(R-2),
よく見る.数え切れない. この後に(L/R-6)が続くものもかなり多いです.
(L-1)(R-6), (L-6)(R-1)
これもとても多いです.
(L-1)(R-7), (L-7)(R-1)
FLICKの方向によっては上と同じになり,逆のときは異なる場合になります.
回レ!雪月花 (LUNATIC)738~745,1209~1216ノーツ目.(L-5)(R-5)
幸せになれる隠しコマンドがあるらしい (MASTER)1030ノーツ目,luna blu (LUNATIC)2565ノーツ目.(L-1)(R-8), (L-8)(R-1)
(L-1)(R-8)は(L-7)(R-5)と同等,(L-8)(R-1)は(L-5)(R-7)と同等.
The wheel to the right (MASTER)1353~1547ノーツ目((L-8)(R-1)が16回),宛城、炎上!! (MASTER)1552~1613ノーツ目,あ・り・ま・す・か? (LUNATIC)222~247,726~813ノーツ目,LAMIA (MASTER)1500~1560ノーツ目付近((L-8)(R-1)が6回).(L-8)(R-2)
(R-2)にBlueが含まれる場合,(L-8)(R-1)と異なりごまかせない.
The wheel to the right (MASTER)1353~1547ノーツ目((L-8)(R-2)が18回),LAMIA (MASTER)1500~1560ノーツ目付近(3回).そうでない場合は(L-7)(R-2),(R-2)(R-7)と同じ.(L-2)(R-8)は登場していない.(L-2)|(L-3)と(R-2)|(R-3)の交互
同色が連続していなければ(L-2)または(R-2)と同じ.これもたくさんあります.例えば階段を(L-2)でR,(R-2)でGBと分業できることを表しています. これの末尾に(L/R-1)や(L/R-6)が来るものも多くありますね. これに(L-1)または(R-1)を混ぜたものもたくさんあり,例えば
Singularity (technoplanet) (MASTER)2006~2023ノーツ目. さらに(L-6)と(R-6)を混ぜたものもまれに見られ,例えばミラージュ・フレイグランス (MASTER)1592~1609ノーツ目,LAMIA (MASTER)1071~1100ノーツ目付近.
HOLDの乗り換え
色のHOLDがあるとし,手
で
のボタンを始点以降押しているとします.もう片方の手
で
のボタンを押している間は
を離してもHOLDの判定が続きます.これによりHOLDを処理する手を変えることができます.これは(L-4),(L-6),(R-4),(R-6)の入れかえと同等のため,処理できる譜面は変わりません.たとえば
バイオレンストリガー (MASTER)1330ノーツ目付近や,シャッキーーン!! (MASTER)1420ノーツ目付近などで利用できます.
ついでに,さっき触れた
HOLDの始点が同時に2つある場合や,HOLDの始点から終点までに同色の別のHOLDが出現している場合
について説明します.
(H-1) HOLDの始点が同時に2つある場合
どちらか片方の手をボタンから離してもHOLD判定が離れることはありません.
R'N'R Monsta (MASTER)1122~ノーツ目などはこれを使わないと押せません. また,この状態からさらに乗り換えが可能です.(H-2) HOLDの始点から終点までに同色の別のHOLDが出現している場合
同色の別のHOLD始点を押した時点で,そちらの手に移れます.
Sound Chimera (MASTER)112~343ノーツ目,R'N'R Monsta (MASTER)1299~ノーツ目,Apollo (MASTER)2466ノーツ目以降などはこれを使わないと押せません.この種類の譜面は意識せずに押せていても実はたくさんあります. また,同色の別のHOLDでなく同色の別のTAPでも同じことができます.
実際の譜面
実際の譜面の一部が,人間が実現可能な操作(L-1)-(L-9),(R-1)-(R-9),(H-1),(H-2)を用いて表せそうなことはわかったので,別の簡単な操作に変換できるかというのを少しだけ見てみます.
Opfer (MASTER)1207~1250ノーツ目
両Greenを押しながら(L/R-3)によって24分を押すのが譜面からすぐ思いつきますが,直前のノーツに続き(R-2)でRG,(L-2)でGBを押すのでも通ります.または,
Viyella's Scream (MASTER)1926~1950ノーツ目同様RBのトリルを両手で行うこともできます.
ω4 (MASTER)159~637ノーツ目
420ノーツ目付近で押したRed, Blueが一番新しいHOLDになるので,(H-2)により古い方の手を離すことができます.
2142ノーツ目付近
(L-2)と(R-6)のそれぞれが16分間隔で連なったものと捉えられますし,(R-9)(L-2),(R-8)の16分交互とも取れます.
脳天直撃 (MASTER)ジャンヌ・ダルクの慟哭 (MASTER)足立オウフwwww (MASTER)1020ノーツ目以降
一般に,同色ノーツが2つ同時に出てきた際は両手を使うことになる一方,そうでない場合は片手で取ることができます.さらに,次のノーツとの巻き込みがなければ余分なノーツを押すことが許容されるため,470~549ノーツ目の緑同時以外と同様に1147~1149ノーツ目のRGB,1280~1287ノーツ目の両RBホールド以外の2色は片手全押し6で取れます. 見た目上同じ
が出現する,
SUPER AMBULANCE (MASTER)1595~1605ノーツ目は(L-2)全押し,(R-2)全押しの8分交互で可能.
おわり
以上のように,譜面が操作可能であるかをわりと形式的に検証することはできて,アルゴリズム的に運指を考えることもできます.もう少しちゃんと定義をすれば譜面定数を定式化することもできます.
明日はもっとISerっぽい記事のはず.
-
よく見る赤青緑のレーンはボタンの入力があると鉛直方向に下がって描画されるのに対し,オンゲキbrightから追加された,ボタンの入力があっても動かないレーンもあります.
Transcend Lights (MASTER)の820~1069ノーツ目などに現れる17色のレーンは,ここで遅れて現れる3色のレーンとは異なる挙動をしています.bright以前にも3色以外のレーン(に見えるもの)が現れたことがありましたが,それらは3色レーンの合成により作られているようです.↩ -
My First Phone (LUNATIC)のようにレーンが消滅している譜面も存在します.↩ -
ニニ (MASTER)169~174ノーツ目は,一見ガードレールがついているように見えますが実はついておらず.判定ラインを通り過ぎた壁を見ると小さく穴が空いています.↩ -
各時刻においてとは言っても,オンゲキは計算機上で動くプログラムゆえにクロックの間にある時間について処理を行うことはできず,おそらくは画面の描画更新と同じタイミングで入力の処理も行っているものと思われます.また物理的なデバイスから入力を受け取っているためわずかながら時間的誤差もあります.↩
-
グリッサンドをノーツに起こしたようなものを指しています.
ヒトリボッチサテライト (MASTER)950ノーツ目付近,Galaxy Blaster (MASTER)36,47ノーツ目など.↩ -
集合
の部分集合の包含関係に関する最大元が