CPU実験思い出し(コンパイラ・シミュ)
2022年のCPU実験の記録です.
書くの遅くない?

班員(コア係)の記事:
danook-programming.hatenablog.com
danook-programming.hatenablog.com
成果
弊班は35億6017万2340命令を52.82sで実行命令数と実行時間ともに1位でした.2022年度から本番が256×256での計測になりまして,過去の記録との比較用に128×128だと10億9776万4043命令を16sくらいです.大体3.3:1くらいのレートですね.
IRとそこで行った最適化はこんな感じです.ISAはリポジトリに上がってる通り変なことはしておらず,アーキテクチャは担当じゃないのでよくわかりません.
- 型検査後の構文木
- 融合変換
- K正規形
- 仮想アセンブリ(SSA)
- 末尾呼び出し最適化
- 不要定義削除
- ジャンプ短縮(後で説明)
- BB内不要store除去(コンパイラ実験の課題として.BB間じゃないので全然効果ない)
- アセンブリ
- 余ったレジスタ活用
- 不要ジャンプ除去(フォールスルー)
レイトレに特化して良いのはアーキテクチャの部分だけです.レイトレのコードに過剰に特化したコンパイラ最適化はしていません.十分に対象を一般化できるんだったら良いんですが,特定の手続きだけ検知して専用の最適化をかけるのってコンパイラがやったらベンチマークチートですよね.融合変換はこの中では一番怪しいですが,変換の対象は十分に小さいコード片なので問題ないという判断をしています.グローバル変数は,OCamlっぽい言語仕様なのにクロージャを使わない方が悪いので問題ないということにしています.
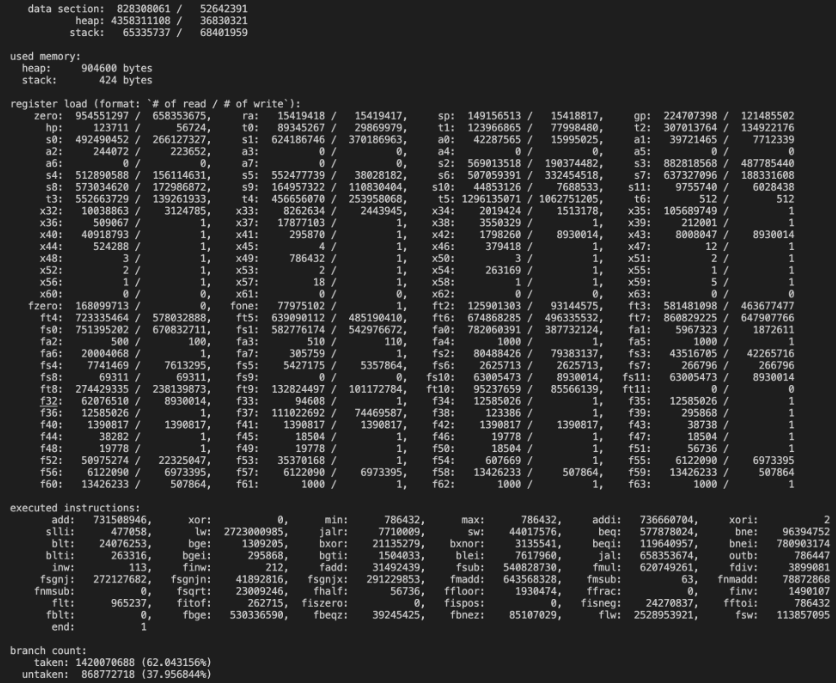
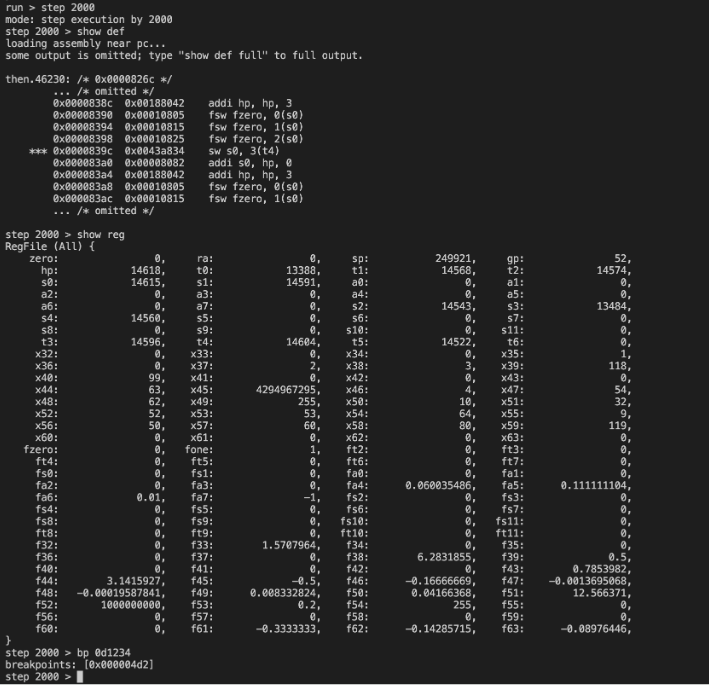
シミュレータは機械語入力でちょっとデバッガ的機能がついた物体になってます.次のようなことができます
- 実行時の命令引数による型検査を実施(これにより,レジスタ割り当てでsave/restoreを忘れていることに気づけた)
- メモリアクセスの場所の分類ごとのアクセス回数を集計(ヒープに頻繁にアクセスされていることがわかり,loop-invariantの発見,CSE/GVNの重要性を認識した)
- 命令ごとの実行回数の集計
- レジスタごとの使用回数の集計
当時のリポジトリは,対面講義のためだけの外出ごとに(電車内でも作業していたため)打たれたwip commitが邪魔なのと,(そもそもまともに動作するのが終盤なので)バージョンを戻す必要がなくcommitが雑につき新規リポジトリで公開しています.
https://github.com/s-ylide/cpuex2022-7-compiler
https://github.com/s-ylide/cpuex2022-7-simulator
mincamlに特有なこと
if式の処理が酷いです.1つの定義に帰着できるというのは大層なことですが,無駄な命令を発生させてまで実装でそれに従う必要はありません.
lwとswが即値を活用できるように実装を変更すると命令数をだいぶ減らせます.displacementを足してレジスタに入れて,その値をアドレスとしてメモリアクセスするより,直接displacement分先のメモリを読みに行ったほうが良いということです.レジスタの使用が減る上にフォワーディングを無くすことに繋がります.
レジスタ割り当てなどアセンブリ付近が本当にやばいので,一目見てわからなかったら自分で実装し直したほうが早く終わる気がします.
mincamlの「まともな」代替となる,CPU実験用のコンパイラを今作っています.これの使用が許可されると良いですね.
minrt.mlに特有なこと
TAの方々の尽力があり,パースが難しい部分が昔より改善しています.過去のCPU実験の記事で指摘されていたような内容はほとんど修正されています.今指摘しているような内容も数年後には変わっている可能性が大いにあります.
整数乗算と整数除算は左右シフトで置換可能なものしか現れません.print_intもちょっと頑張れば定数畳み込みできて消えるので,この内部実装で使うこともありません.
交差判定かなにかで,if xorがそこそこ頻発します.これ専用の命令を用意すると良いかもしれません.
複合命令とか増やしても結構命令数には余裕があるので,スケジューリングしてRISC-Vのcompressed命令とかVLIWをやるとお得かもしれないです.でもレイトレでは並列に実行できる計算がそんなに多くない気がします.
contest.sld以外にも20個くらいSLDファイルが提供されるので,先にこれらがまともに動くかのデバッグをすると良いでしょう.base.sldでは踏まないがcontest.sldでは踏む命令などもあり,シミュレータの機能が充実していれば単に実行を追う以上の情報を得られるはずです.
レイトレのアルゴリズム的に,各点ごとに,各方向,各オブジェクトごとに計算をするので,ループが何回も回っています(プログラムはアセンブリで10000行程度なのに数十億命令を実行するのはそのせい).ループ回数を適切に見積もれば最適化の余地があると思います.
タプル平坦化
私は結局よくわかっていません.型推論以下でメモリアレンジメント決定より上のレイヤーの話っぽくて,本当に真面目にやるならglobals.mlの型付けで特殊なことをしないと効果が出ないはずです.具体的には,配列の配列をnull pointer的なArray.make 0 nからなる配列で初期化しており,アクセスのタイミングによっては配列の値に依存してアクセス位置が変わってしまうみたいな感じでした.手で証明するのは簡単ですが,コンパイラ内で検証するのは結構骨の折れる作業です.
コンパイラ最適化
たのしいコンパイラ最適化ですが,限度があって,普通のアーキテクチャ(かつシングルコア)向けでは実行命令数11億(128×128)程度に落ち着くと思われます.実行時間に関しても,大量のload命令を改善しない限りコンパイラができることは少ないはずです.本気で高速化したいならISAをちょっといじるだけではだめで,コアにちゃんと関わりながらアーキテクチャを見直すべきです.なので4人班ならコア係/コンパイラ・コア係/コア・メモリ係/シミュレータ・FPU係,が理想のパーティだと思っています.単位要件は係ごとですが別の係の人に手伝ってもらうのは有効みたいなので,実態がこんな感じでも多分問題ありません.
以下は最終発表のスライドに書いてあった内容です.
効果があったコンパイラ最適化
どのくらい命令数が減ったかとかを計測しなかったので,何がどのくらい効いているのかわかりません.最適化ありきで実装を省略したものもあり,最適化を外して計測するということも難しいです.
CSE
メモリアクセスを減らしたかったのでエイリアス解析も同時に行った.
ループ検知・インライン展開
ループ検知はSSAを意識してphi相当のものを計算すると良い.
インライン展開は命令メモリの許す限り行ったほうが良い. 関数呼び出し規約から解放され, 不要定義除去・定数畳み込みなどその他の最適化に大いにつながる
ループ検知はインライン展開の対象になるIRで行ったほうが良い.
mincaml改造なら KNormal.t
実行に使ったコードは,「600行以内または一度のみ使用される,非再帰関数を展開する」戦略のもの
最適化パスの集中
他の最適化と合わさって爆発的に命令が減る!インライン展開と同じIRで最適化を進めるべき
(2022年度の他のコンパイラ係は,最適化を実行するIRのレイヤーがかなり低めになっている傾向にありました.K正規形がだいぶ素直で扱いやすい形をしているので,悩んだらここの時点で種々の最適化を行ったほうが良いです.)
グローバル変数
関数がキャプチャする変数は,レイトレでは定数と配列のみである.lambda liftingは無意味.
クロージャを完全に消滅させることができるため,クロージャ変換は実装してない
実装としては,値をコンパイル時に計算してdata sectionに配置
ジャンプ短縮
空の基本ブロックへのジャンプ,のような無駄なジャンプの連鎖をできる限り短縮.合流があるので,単につなげるだけでは下手するとプログラムサイズが大きくなる
if式が生成する小さい基本ブロックがどうやら非常に多かったらしく,条件式中のif式とか,thenかelseの片方がunitの場合とかはこの最適化がありえないくらい効く.
余ったレジスタでグローバル変数のレジスタ化
レジスタ割り当てがそこそこ優秀なので,使わないレジスタとか出てくる. 引数用レジスタとかもABI上用意しているが実際使われないことがある
ポインタ取得とかがされない,純粋なload/storeからなるものをレジスタに置く戦略 (実レジスタに対するmem2regみたいなこと)
どれくらい効いたかわからないがメモリアクセスはもとより1割くらい減った. float定数もこれに含まれるが,使用回数(ループかどうかは判定してない←これが良くない)の多い順にレジスタ化をした. intはグローバル変数も定数も全部レジスタ(64個)に乗っかったため, まだ余っている
(レジスタが余ったということは最適な割り当てよりも損をしていることになります.OoOを考えるならround-robinっぽいmincamlデフォルトのレジスタ割り当ての方が良いかもしれません.)
日記
この日記はslackの壁打ちチャンネルの内容から抜粋したものです.CPU実験は90日以上に渡って行われるため,slackを使うのはやめてdiscordにサーバー建てるとかの方が良いです.
見つけたバグについて少しだけ書いてあるけど,コンパイラをスクラッチする人以外はこの手のバグを一切踏まないはずなのであんまり役に立たないと思います.役に立つかどうかでいうとコンパイラをスクラッチしてシミュレータ係を兼任する人なんていないのでそもそも何の役にも立たないか.
10/18ごろ 開始
11/30 パーサー・アセンブラを作った.リンカもどきもできたので下から作っていくことに
12/1 IOとかについて考え始めた
12/2 レジスタ割り当てを考え始めた.同期からレジスタ割り当ての資料をもらい,読んで実装を始める
12/15 活性解析おわり
このへんでレイトレのコンパイルを通そうとし始める
1/3 型推論できた
1/4 コンパイルが通ってしまったためコンパイラのバグ探しを始める.ここから20日間がテストもあり一番つらかった.
1/7ごろ CFGのprogram pointの付け方がずれてたことに気づく.block parameterを導入したせい
1/8 sumがシミュ完動
ネストしたifのバグを発見!LLVMのfront end相当のものをちゃんと書けばよかった
1/9 スタックのアロケート忘れを発見.fibがシミュ完動
1/10 ネストしたifのバグを修正 ifと再帰関数を含む関数がシミュ完動
1/11 デコードを間違えていたことに気づく.特にauipc.auipcを使う必要なくなったので回避
1/12 比較演算のパースが間違ってた
ここからコンパイラのバグが体感全然見つからなくなり,シミュでデバッガを実装して潰すことに.これを1/24まで続ける. Aセメスター始まってからほとんどCPU実験しかしてないからろくに解答用紙を埋められず,余りまくった試験時間中もコンパイラのバグのことを考えていた.
1/14 ようやくレジスタの復帰忘れをしていることに気づく
1/21 flwの引数が大きすぎることが判明,word-addressingにすることで回避
1/24 not->xorの翻訳を間違えたことに気づく.レイトレがシミュ完動!
2/14まで ずっと最適化.1/24までの20日間の苦しさと,以降の20日間の楽しさの落差は忘れられない.知能システム論の単位を落とす
夏休みの宿題を最終日に片付けてるような人間とは思えないほど序盤から頑張ってはいたんですが,それでも兼任とスクラッチは仕事を抱えすぎだったようです.実装しながら最適化を同時に進めていたため最適化にかけた時間は20日よりは多くなっています.ちなみに丸20日よりも多いです.
コア係さんも書いてましたけど,デバッグやデバッグのための工数が必要で最初に書いた表通りになるわけないので,仕事を丁寧に割り振って進めるのではなく,密に連絡を取ってとにかく開発したほうが良いです.
コンパイラ係を志望する方へ
コアはコンパイラを待つので最低限動くものを早めに出せると良いです.mincamlの改造ならISA対応と少しで動かせるので,まずそれはさっさと実装してください.私は動くコンパイラを提出したのが相当遅くなったので全く人のこと言えませんし,特に特定個人を責めているわけではないんですが,コンパイラができないと班員に大きな迷惑がかかります.
多くの人はコンパイラをスクラッチする必要はありません.特殊な最適化を頑張りたいならなおさらしない方が良いです.レギュレーション的に使って良いのかわかりませんけど,LLVM等の既存のコンパイラ基盤を活用してもっと考えるべきことに時間を使ったほうが良いです.必修の単位とかね.
実行命令数削減と実行時間短縮に最も貢献するのはコンパイラ係です.CPU実験で遊びたいならコンパイラ係がおすすめです.よくある最適化を一通り行うだけでも十分命令数を減らせますし,複数の最適化が合わさってさらに最適化が進むこともあり,最適化を行うフェーズに入ってからはだいぶ面白いゲームができます.
私が超えられなかった10億命令の壁を破壊してくれることを期待しています.
シミュレータ係を志望する方へ
コンパイラはシミュレータを待つので最低限動くものを早めに出せると良いです.アセンブラがなくても最悪アセンブリを手書きしてデバッグを進めるべきです.
11月ごろから1月にかけて,シミュレータを実装したら多分やることがなくなるので,班員の仕事をうまく巻き取ってください.
ソフトウェアが普通に書けるなら別に全然難しくないし,単位要件がなんか重くなってることを除けば楽な仕事です.独自のISAならデバッガみたいなものを作ってあげるとコンパイラ係がとても助かります.この学科はまともにプログラムを書ける人がそう多くないので,周りより書ける自信があるなら買って出ましょう.